Harkirat Behl

Principal Researcher
Microsoft Research
Research Interest: Data Centric AI - Synthetic Data
Education
PhD, University of Oxford, 2021 Advisors: Phil Torr, M. Pawan Kumar
BTech, Indian Institute of Technology, Kanpur, 2018
Research
[New] Phi-4 Technical Report
(#) Marah Abdin, Jyoti Aneja, Harkirat Behl, and
arXiv 2024
![]() 3,300,000
3,300,000
![]() 2,100,000
2,100,000



Phi-3: A Highly Capable Language Model Locally on Your Phone
(#) Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan,
arXiv 2024
![]() 27,207,626
27,207,626
Phi-3-mini
Phi-3-small
Phi-3-medium
Phi-3-vision
In Popular Media

Peekaboo: Interactive Video Generation via Masked-Diffusion
Yash Jain*, Anshul Nasery*, Vibhav Vineet, Harkirat Behl
CVPR 2024
CVPR 2024 W (Invited Oral)

Scaling the Convex Barrier with Sparse Dual Solvers
Alessandro De Palma, Harkirat Behl, Rudy Bunel, Philip Torr, M. Pawan Kumar
JMLR 2024
Tight and efficient neural network bounding is crucial to the scaling of neural network verification systems. Many efficient bounding algorithms have been presented recently, but they are often too loose to verify more challenging properties. This is due to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise-linear activations exists, it comes at the cost of exponentially many constraints and currently lacks an efficient customized solver. We alleviate this deficiency by presenting two novel dual algorithms: one operates a subgradient method on a small active set of dual variables, the other exploits the sparsity of Frank-Wolfe type optimizers to incur only a linear memory cost. Both methods recover the strengths of the new relaxation: tightness and a linear separation oracle. At the same time, they share the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we can obtain better bounds than off-the-shelf solvers in only a fraction of their running time, attaining significant formal verification speed-ups.
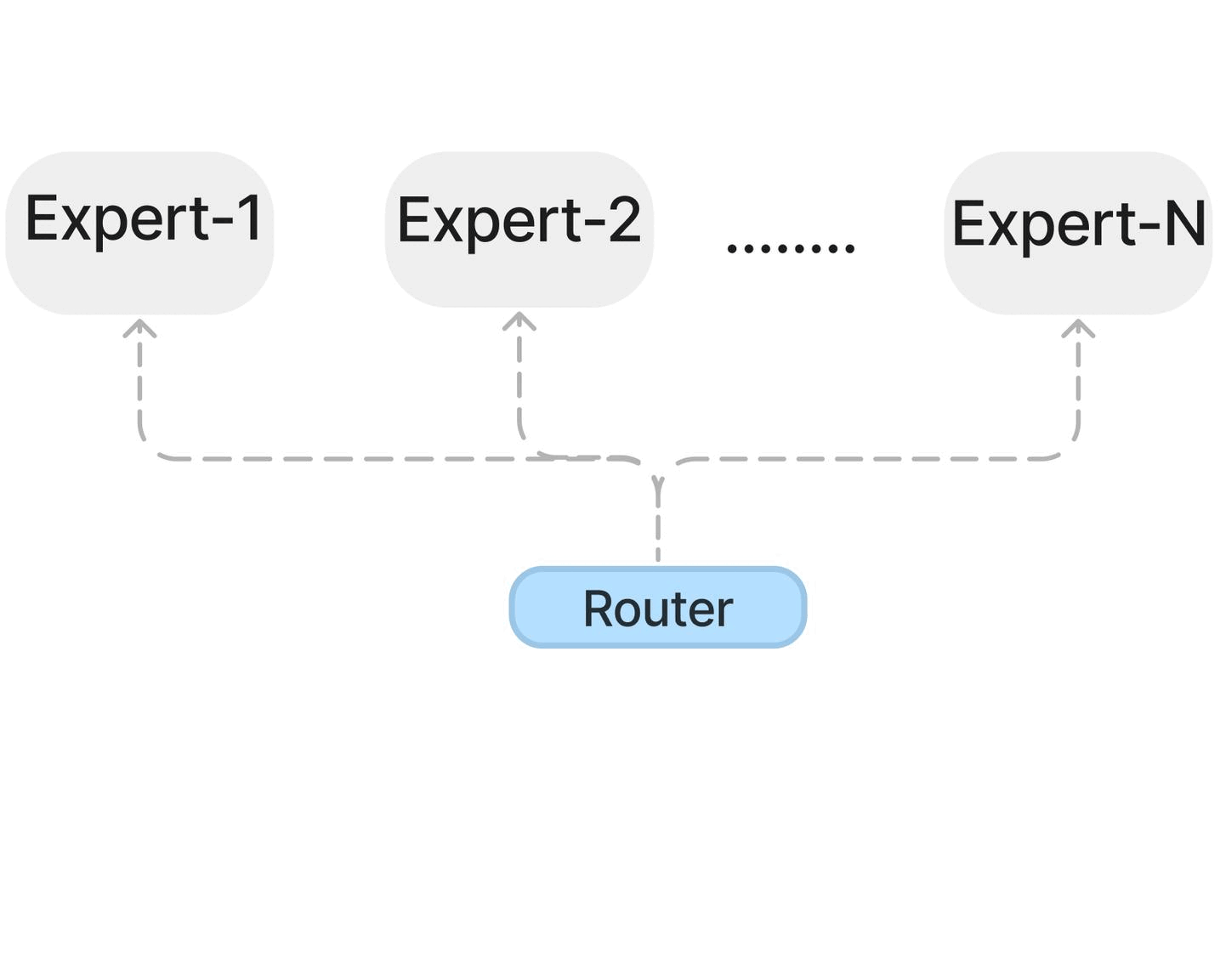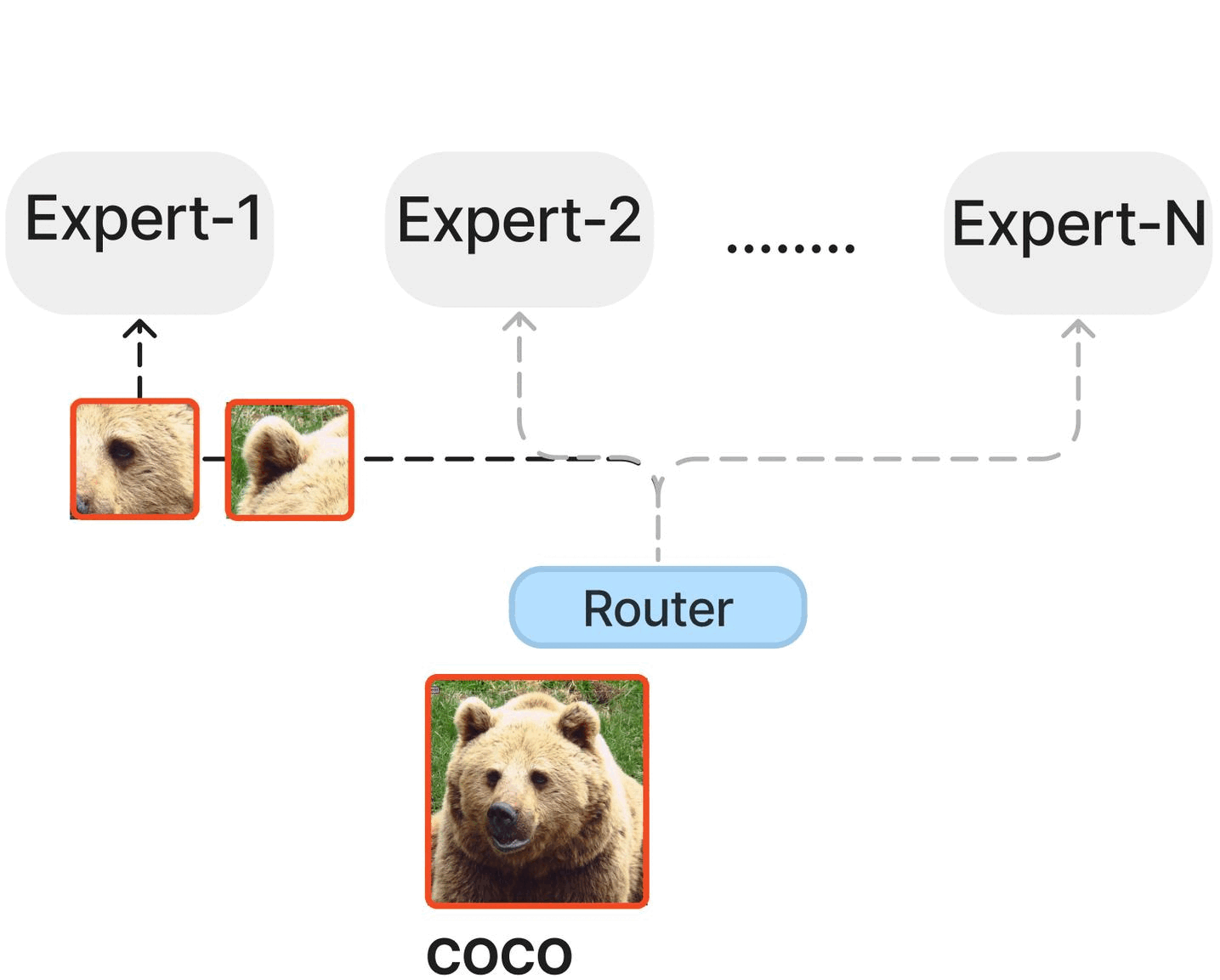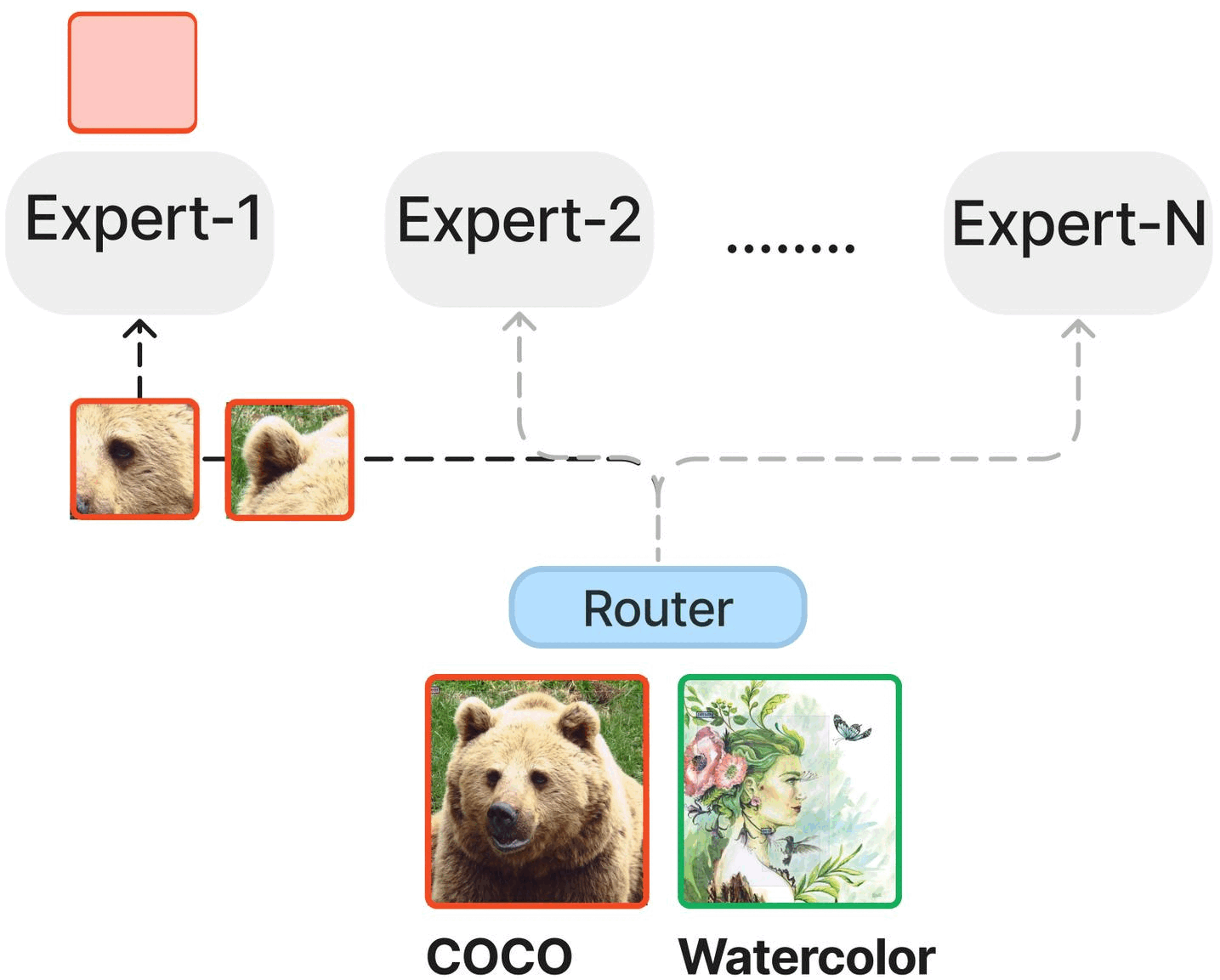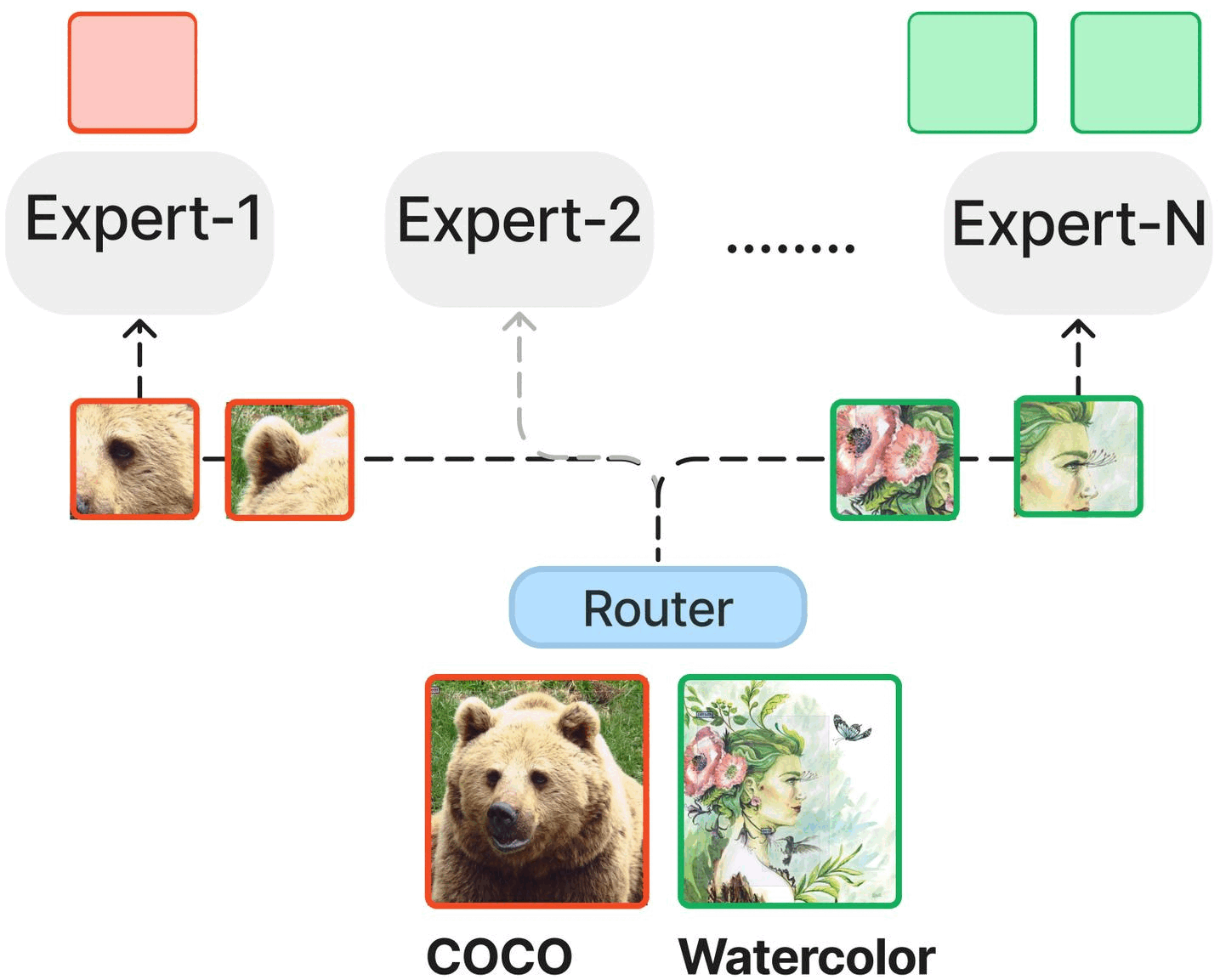
Textbooks Are All You Need
(#) Suriya Gunasekar, Yi Zhang, Caio Cesar Teodoro Mendes,
arXiv 2023
![]() 132,653
132,653

X-Decoder: Generalized Decoding for Pixel, Image and Language
Xueyan Zou, Zi-Yi Dou, Jianwei Yang,
CVPR 2023

Neural-Sim: Learning to Generate Training Data with NeRF
Yunhao Ge, Harkirat Behl, Jiashu Xu,
ECCV 2022


Overcoming the Convex Barrier for Simplex Inputs
Harkirat Behl, M. Pawan Kumar, Philip Torr, Krishnamurthy (Dj) Dvijotham
NeurIPS 2021
Scaling the Convex Barrier with Active Sets
Harkirat Singh Behl*, Alessandro De Palma*, Rudy Bunel, Philip Torr, M. Pawan Kumar
ICLR 2021
Tight and efficient neural network bounding is of critical importance for the scaling of neural network verification systems. A number of efficient specialised dual solvers for neural network bounds have been presented recently, but they are often too loose to verify more challenging properties. This lack of tightness is linked to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise linear activations exists, it comes at the cost of exponentially many constraints and thus currently lacks an efficient customised solver. We alleviate this deficiency via a novel dual algorithm that realises the full potential of the new relaxation by operating on a small active set of dual variables. Our method recovers the strengths of the new relaxation in the dual space: tightness and a linear separation oracle. At the same time, it shares the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we obtain better bounds than off-the-shelf solvers in only a fraction of their running time and recover the speed-accuracy trade-offs of looser dual solvers if the computational budget is small. We demonstrate that this results in significant formal verification speed-ups.
Progressive Skeletonization: Trimming more fat from a network at initialization
Pau Jorge, Amartya Sanyal, Harkirat Singh Behl, Philip Torr, Gregory Rogez, Puneet Dokania
ICLR 2021
Recent studies have shown that skeletonization (pruning parameters) of networks at initialization provides all the practical benefits of sparsity both at inference and training time, while only marginally degrading their performance. However, we observe that beyond a certain level of sparsity (approx 95%), these approaches fail to preserve the network performance, and to our surprise, in many cases perform even worse than trivial random pruning. To this end, we propose an objective to find a skeletonized network with maximum foresight connection sensitivity (FORCE) whereby the trainability, in terms of connection sensitivity, of a pruned network is taken into consideration. We then propose two approximate procedures to maximize our objective (1) Iterative SNIP: allows parameters that were unimportant at earlier stages of skeletonization to become important at later stages; and (2) FORCE: iterative process that allows exploration by allowing already pruned parameters to resurrect at later stages of skeletonization. Empirical analysis on a large suite of experiments show that our approach, while providing at least as good a performance as other recent approaches on moderate pruning levels, provide remarkably improved performance on higher pruning levels (could remove up to 99.5% parameters while keeping the networks trainable). Code can be found in https://github.com/naver/force.

STEER: Simple Temporal Regularization For Neural ODEs
Arnab Ghosh, Harkirat Singh Behl, Emilien Dupont, Philip Torr, Vinay Namboodiri
NeurIPS 2020
Training Neural Ordinary Differential Equations (ODEs) is often computationally expensive. Indeed, computing the forward pass of such models involves solving an ODE which can become arbitrarily complex during training. Recent works have shown that regularizing the dynamics of the ODE can partially alleviate this. In this paper we propose a new regularization technique: randomly sampling the end time of the ODE during training. The proposed regularization is simple to implement, has negligible overhead and is effective across a wide variety of tasks. Further, the technique is orthogonal to several other methods proposed to regularize the dynamics of ODEs and as such can be used in conjunction with them. We show through experiments on normalizing flows, time series models and image recognition that the proposed regularization can significantly decrease training time and even improve performance over baseline models.
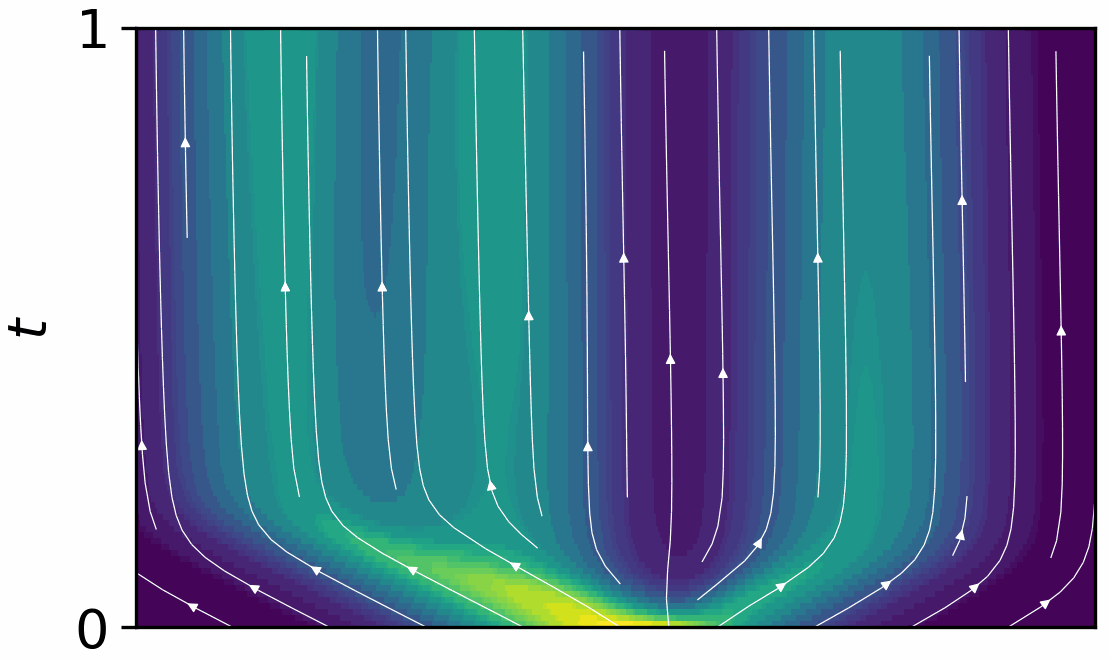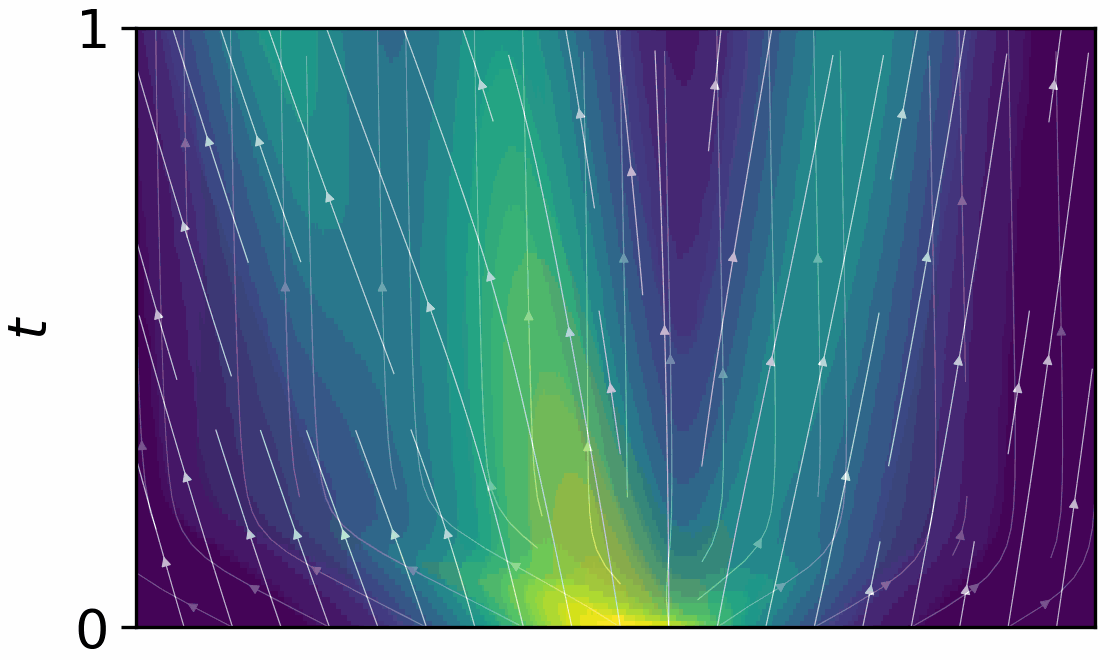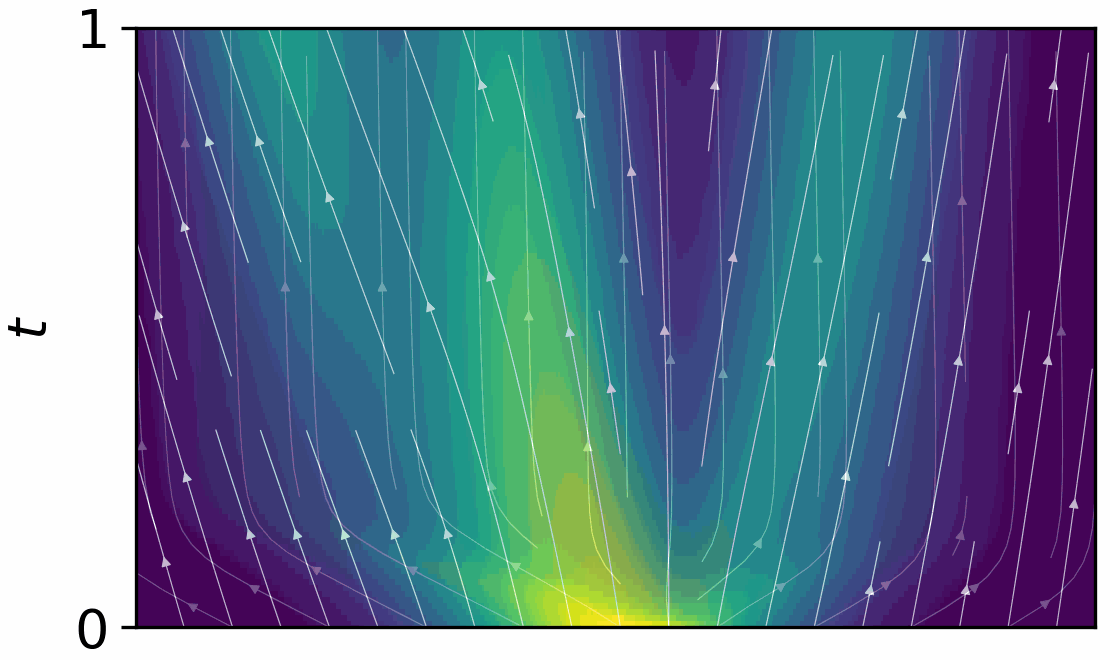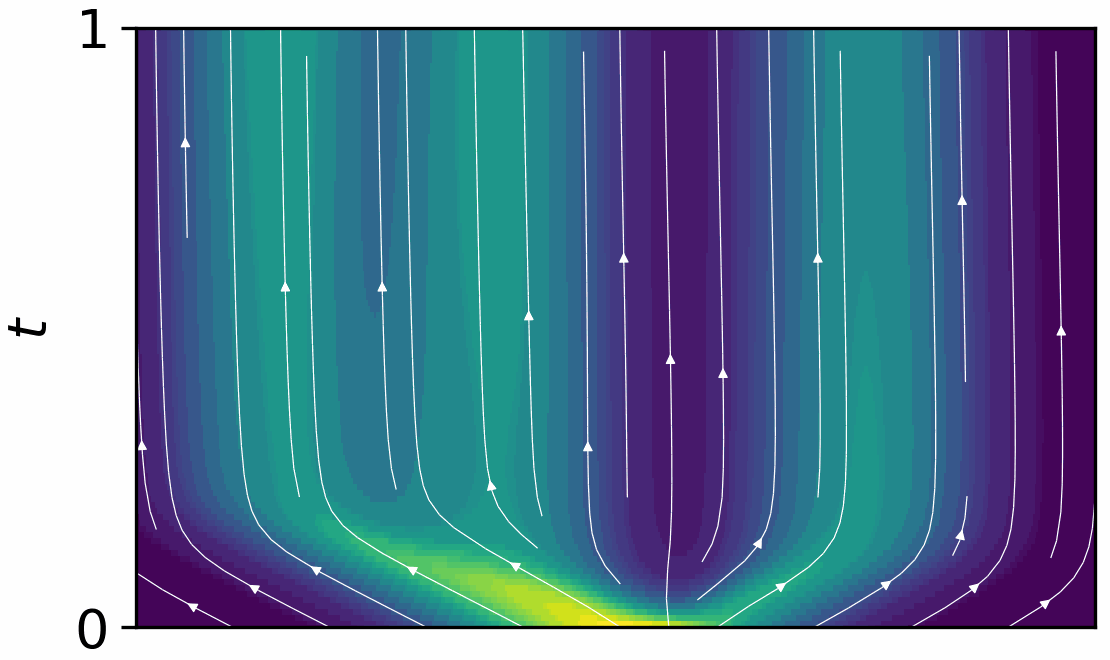
AutoSimulate: (Quickly) Learning Synthetic Data Generation
Harkirat Singh Behl, Atılım Güneş Baydin, Ran Gal, Philip Torr, Vibhav Vineet
ECCV 2020
Simulation is increasingly being used for generating large labelled datasets in many machine learning problems. Recent methods have focused on adjusting simulator parameters with the goal of maximising accuracy on a validation task, usually relying on REINFORCE-like gradient estimators. However these approaches are very expensive as they treat the entire data generation, model training, and validation pipeline as a black-box and require multiple costly objective evaluations at each iteration. We propose an efficient alternative for optimal synthetic data generation, based on a novel differentiable approximation of the objective. This allows us to optimize the simulator, which may be non-differentiable, requiring only one objective evaluation at each iteration with a little overhead. We demonstrate on a state-of-the-art photorealistic renderer that the proposed method finds the optimal data distribution faster (up to 50x), with significantly reduced training data generation (up to 30x) and better accuracy (+8.7%) on real-world test datasets than previous methods.
Meta-Learning Deep Visual Words for Fast Video Object Segmentation
Harkirat Singh Behl, Mohammad Najafi, Anurag Arnab, Philip Torr
IROS 2020 (Oral)
NeurIPS 2019 W (Oral)
Accurate video object segmentation methods finetune a model using the first annotated frame, and/or use additional inputs such as optical flow and complex post-processing. In contrast, we develop a fast algorithm that requires no finetuning, auxiliary inputs or post-processing, and segments a variable number of objects in a single forward-pass. We represent an object with clusters, or "visual words", in the embedding space, which correspond to object parts in the image space. This allows us to robustly match to the reference objects throughout the video, because although the global appearance of an object changes as it undergoes occlusions and deformations, the appearance of more local parts may stay consistent. We learn these visual words in an unsupervised manner, using meta-learning to ensure that our training objective matches our inference procedure. We achieve comparable accuracy to finetuning based methods, and state-of-the-art in terms of speed/accuracy trade-offs on four video segmentation datasets.

Alpha MAML: Adaptive Model-Agnostic Meta-Learning
Harkirat Singh Behl, Atılım Güneş Baydin, Philip Torr
ICML 2019 W
Model-agnostic meta-learning (MAML) is a meta-learning technique to train a model on a multitude of learning tasks in a way that primes the model for few-shot learning of new tasks. The MAML algorithm performs well on few-shot learning problems in classification, regression, and fine-tuning of policy gradients in reinforcement learning, but comes with the need for costly hyperparameter tuning for training stability. We address this shortcoming by introducing an extension to MAML, called Alpha MAML, to incorporate an online hyperparameter adaptation scheme that eliminates the need to tune meta-learning and learning rates. Our results with the Omniglot database demonstrate a substantial reduction in the need to tune MAML training hyperparameters and improvement to training stability with less sensitivity to hyperparameter choice.
![]()
Incremental Tube Construction for Human Action Detection
Harkirat Singh Behl, Michael Sapienza, Gurkirt Singh, Suman Saha, Fabio Cuzzolin, Philip Torr
BMVC 2018
Current state-of-the-art action detection systems are tailored for offline batch-processing applications. However, for online applications like human-robot interaction, current systems fall short. In this work, we introduce a real-time and online joint-labelling and association algorithm for action detection that can incrementally construct space-time action tubes on the most challenging untrimmed action videos in which different action categories occur concurrently. In contrast to previous methods, we solve the linking, action labelling and temporal localization problems jointly in a single pass. We demonstrate superior online association accuracy and speed (1.8ms per frame) as compared to the current state-of-the-art offline and online systems.

Recent Talks
- Microsoft AI Development Acceleration Program May 2025
- Meta AI, Apr. 2025
- Plutos.dev AI, Mar. 2025
- MSR Project Green Reasoning Workshop, Mar. 2025
- Brazilian Podcast - IA Sob Controle, Feb. 2025
- Microsoft AI Frontiers Anniversary, Nov. 2024
- Microsoft IC3-AI Team Talk, Oct. 2024
-
Microsoft Reverb, Sep. 2024
(Annual offsite with 100 Microsoft Senior Director level leaders)
- HMG Tech Intelligence Team, June 2024
- Microsoft AI Compilers Workshop, May 2024
- GitHub AI for Code Reading Group, May 2024
- Microsoft PoAA (Pals of Autonomous Agents), May 2024
- JEM Council Meeting, Apr. 2024
(Microsoft E+D Research Leaders)
- Perception Cloud Team, Zurich, Mar. 2024
- Microsoft AI Frontiers Offsite, Jan. 2024
- Bill & Melinda Gates Foundation Representatives, Dec. 2023
Interns
- Jack Cai (Princeton, 2025)
- Behrooz Tahmasebi (MIT, 2024)
- Anshul Nasery (UW, 2023)
- Jiashu Xu (Harvard, 2023) → (Research Scientist, Nvidia)
- Yash Jain (Georgia Tech, 2023) → (Applied Scientist, Microsoft)
- Mohammad Derakhshani (UvA, 2023)
- Robbie Netzorg (UC Berkeley, 2022)
- Yunhao (Andy) Ge (USC, 2021) → (Research Scientist, Nvidia)
Resources
- How to Write a Research Paper, Give a Research Talk (by Simon Peyton Jones)

