Meta Learning Deep Visual Words for Fast Video Object Segmentation
Harkirat Singh Behl, Mohammad Najafi, Anurag Arnab, Philip H.S. Torr
Conference on Neural Information Processing Systems (NeurIPS) 2019 Workhop on Machine Learning for Autonomous DrivingOral Presentation

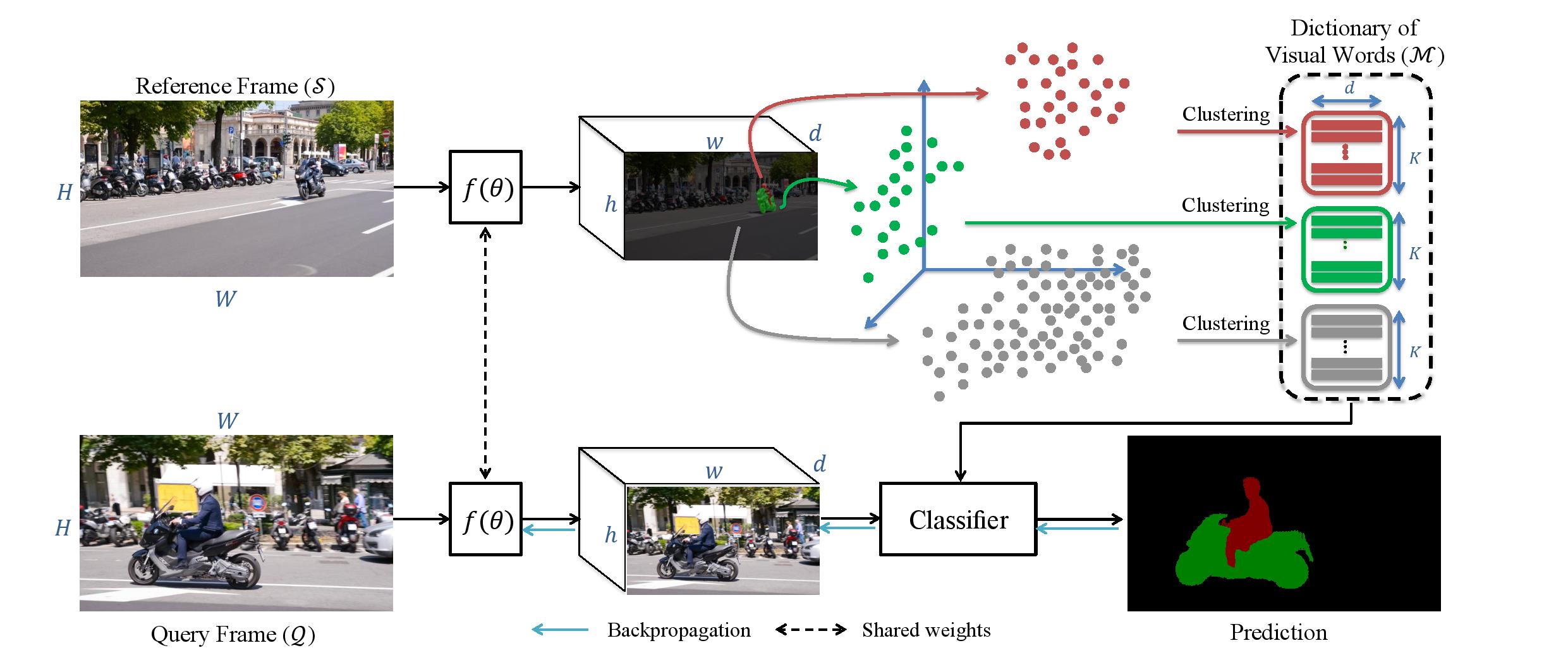
Figure: Video object segmentation using a dictionary of deep visual words. Our proposed method represents an object as a set of cluster centroids in a learned embedding space, or "visual words", which correspond to object parts in image space (bottom row). This representation allows more robust and efficient matching as shown by our results (top row). The visual words are learned in an unsupervised manner, using meta-learning to ensure the training and inference procedures are identical. The t-SNE plot on the right shows how different object parts cluster in different regions of the embedding space, and thus how our representation captures the multi-modal distribution of pixels constituting an object.